Today let’s look at one of the most fundamental methods of
classification in machine learning and statistics- Logistic regression.
To understand a general supervised classification problem
let us take an example of spam classification. Our training data consists of a
number of emails and since it is a supervised problem, we also know if they are
spam(Y=1) or ham (not spam, Y=0). For feature vector X (n dimensional) , we
might have each dimension corresponding to a word occurrence, being 0 or 1
depending on whether or not is present in that mail. So a spam may have 1s in
the dimensions corresponding to words like ‘offer’, ‘free’, ‘Viagra’ etc. Our
aim here will be training our weight vector $\theta$ and decide some threshold
t such that:
hypothesis = $h_{\theta}(x)$ > t
for all spam
$h_{\theta}(x)$<=
t for all ham
Value of threshold is determined based on that particular
application depending on the tradeoff we want to have between false positives
and false negatives. For concreteness let’s assume the threshold to be 0.5.
After training our weight vectors we move on to the test data and try to model
$P(Y|X,h_{\theta})$ and classify our samples.
HYPOTHESIS FUNCTION:
Since the hypothesis models the probability of a particular
X falling in a category Y given $\theta$, it makes sense that it is a value
bounded between 0 and 1. Hypothesis that we used in linear regression was $\theta^{T}.X$.
In order to keep it bounded, in logistic regression we use an activation function
called sigmoid function which is defined as:
$sigmoid(z) = \frac{1}{1+e^{z}}$
So our hypothesis becomes:
$h_{\theta}(x)=sigmoid(\theta^{T}.X)=
\frac{1}{1+e^{\theta^{T}X}}$
Graphically it looks something like this:

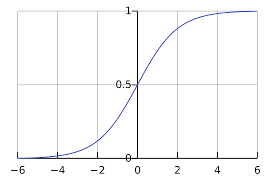
COST FUNCTION:
In linear regression we used average of squared error
between hypothesis and labels as our cost function. But since our hypothesis
here is non-linear, we don’t get a nice convex curve as our cost function here.
To make it convex cost function $J (X| Y, h_{\theta}(X))$ is defined as follows
in logistic regression:
When Y=1:
$J (X| Y, h_{\theta}(X))= -log(h_{\theta}(X))$
When Y=0:
$J (X| Y, h_{\theta}(X))= -log(1-(h_{\theta}(X))) $
This can be written in a more compact form like this:
$ J (X| Y, h_{\theta}(X))= -[Y.log(h_{\theta}(X)) + (1-Y)
.log(1-(h_{\theta}(X)))]$
Plot the cost function separately for Y=1 and Y=0 with the
hypothesis function and try to convince yourself why it should make sense.
Once you have the cost function learning the weight vectors
boils down to a pure optimization problem. To solve this you can either use
gradient descent as discussed in the linear regression post or you can not get
your hands dirty and piggyback one of the off-the-shelf optimization function
solvers available.
REGULARIZATION:
There is a problem with what we have discussed thus far. If
the number of features is large this can build a very complicated, convoluted
model with very large weight values so as to perfectly fit the training data.
This might sound good, but the problem is that our model will be very biased
towards the traing data and will not generalize well for the test data which,
as a matter of fact, is our main objective. To do away with this problem we use
the method of regularization which puts a penalty on the magnitude of the
weight vectors and does not let the model overfit.
This is done by modifying our cost function as follows:
$ J (X| Y, h_{\theta}(X))= -[Y.log(h_{\theta}(X)) + (1-Y)
.log(1-(h_{\theta}(X)))]$ +$\frac{\lambda}{2m}\sum\theta^{2}$
The last part in the regularization term and
$\lambda$ is called the regularization parameter.
The value of $\lambda$ should be selected wisely. If it is
too high you penalize the weight vectors too much and the model does not fit
even the training data properly (underfitting). On the flip side if you are
being too cautious and select a very small value for lambda, regularization hardly
does what it is supposed to and you have overfitting.